Real‑Time Fraud Detection on AWS

Recently, I discovered Kaggle, an ML website that hosts huge repositories of training data of all kinds. One of them that caught my attention, for reasons I'll elaborate on below, was a dataset of credit card transactions, some of which were fraudulent. Using this dataset, I built a practical fraud‑detection pipeline on AWS to classify card transactions as legitimate or fraudulent while controlling review volume.
The unique thing about this dataset is that fraudulent transactions are extremely rare (about a rate of 0.17%), so ranking quality and threshold choice matter way more than raw accuracy. The goal here is to capture as much fraud as possible while manually reviewing only a tiny fraction of traffic and minimizing false positives. Final actions follow a three‑way policy: ALLOW, HOLD, or BLOCK.
I started in S3 with a raw CSV of transactions and spun up a Glue crawler to fingerprint the schema. From there, I set a dedicated workgroup and results bucket, then ripped out training/validation splits from the dataset in Athena using UNLOAD. There was some difficulty when I realized that the model expects the label first, followed by the 30 features in the exact order they were trained on, so I had to explicitly cast every field to plain text to ensure a lack of stray quotes or type mismatches when XGBoost parses the stream later.
Before moving on, I sanity-checked one of the output “part” files in S3: the first token is a 0/1 label, followed by 30 comma-separated numeric values, and there’s no header line.
Training (SageMaker)
With the data staged, I used the built-in XGBoost container in SageMaker. To make training fast and cheap,
I fed the data using Pipe mode with Gzip compression, which streams the UNLOAD parts directly
from S3 into the container. In order to handle fraud being extremely rare, I set a class-weighting term
(scale_pos_weight=578) so the learner doesn’t ignore the minority class. 578 is the
ratio of not-fraud to fraud in the big dataset (284,315 / 492 ≈ 578), and this ratio should be almost the same
in the training data. Specifically, this upweighs every fraud example by 578 times so the booster pays attention to
them despite ~0.17% prevalence. The last thing I set up was early stopping; if the validation AUC stopped improving
for a while, training would cut off automatically to avoid overfitting.
The training job surfaces live metrics to CloudWatch and the SageMaker console, so I could watch the
validation-auc rise, flatten, and finally trigger early stopping around a few dozen rounds.
The job packaged the best model into model.tar.gz in S3.
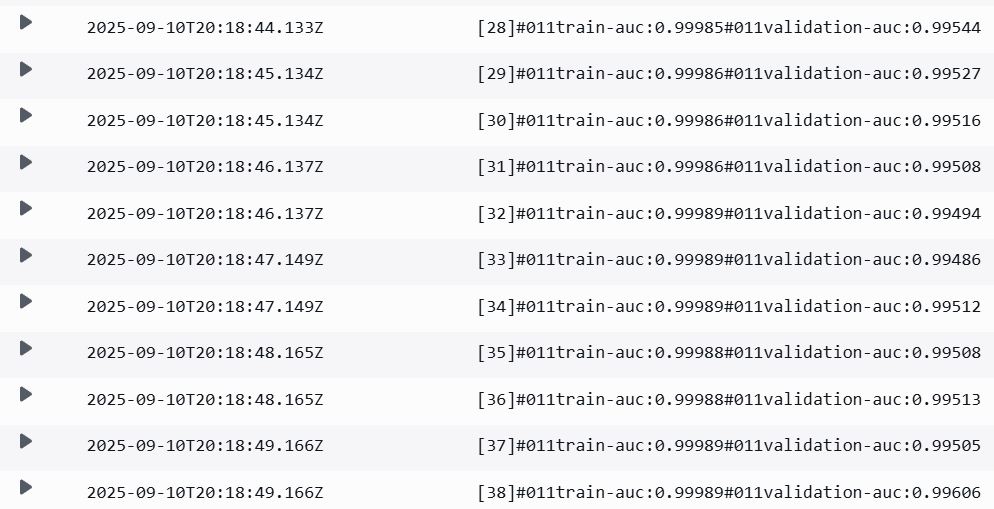
SageMaker training: validation-AUC rises, plateaus, and triggers early stopping.
Rather than pay to keep an endpoint around, I evaluated offline by downloading the model artifact and the validation split and scoring everything locally using the same XGBoost library the container uses.
The evaluation focuses on imbalanced-class metrics. First, I report two figures: ROC-AUC and PR-AUC. ROC-AUC measures ranking quality over all thresholds. It answers: “If I pick a random fraud case and a random legit transaction, how often does the model score the fraud higher?” It’s threshold-free, but can be overly optimistic when positives are rare. PR-AUC focuses on the positive class. It answers: “As I move down the ranked list, how much fraud am I catching (recall) and how clean are my catches (precision)?” For rare events, PR-AUC is the metric that actually reflects operational reality. Then, I run a second program to search over thresholds to find the best-F1 cutoff, which is a balanced point between precision (“of the items I flagged, how many were actually fraud?”) and recall (“of all actual fraud, how many did I catch?”).
My results:
0.99296 — excellent ranking; the model orders fraud above legit almost perfectly.0.83834 — far above the random baseline (~0.00167), meaning the top of the list is dense with true fraud.0.7991 →
TP=86, FP=19, TN=56,752, FN=9
(Precision 0.827, Recall 0.905).
How this is chosen: For each threshold I compute Precision and Recall from (TP,FP,TN,FN), then calculate F1. The threshold that maximizes F1 (0.7991 here) is reported as “best-F1.”

Local evaluation.
These aren't bad metrics, but definitely have room for improvement. In many fraud programs, auto-declines need very high precision (often 95%+), and no single threshold that I calculated, even the mathematically optimal one of 0.7991, achieved that without sacrificing too much recall. There were just too many transactions that were a little suspicious, but not enough to flag without also flagging a bunch of legitimate transactions. So I pivoted to a two-tier policy that separates suspicious transactions into 2 categories: "Decline immediately," and "send to human review".
Two-tier policy:
What this achieved on validation:
0.135% This many transactions were auto-blocked without review.0.326 This means that roughly 1/3 of human-reviewed items turned out to be fraudulent.0.979 This is how much of fraud was captured with the new policy. 98% is a much better number!In plain terms: by adding a manual review step for 0.366% of traffic, my success rate for capturing fraud went from 90% to 98%.
PackagingThis repository includes the Athena SQL that creates deterministic splits, a short document of the SageMaker training configuration (image, hyperparameters, input prefixes), and 2 compact scoring scripts that reproduce the reported metrics and thresholds on a fresh machine.