Chatlog Archivism and Processing: The Full Data Pipeline
Ever since the pandemic in 2020, my high school friends and I have been keeping in touch using the voice/text communication platform Discord. Over the years, I began to realize that the private Discord server we had been using to make plans, chat, share clips from our gaming sessions, and update each other about our lives would one day be an artifact of incalculable nostalgic value to us, and it was irresponsible to let it all sit precariously in the cloud where it could be deleted at any time.
Since I was the resident computer science major, I wrote a script to backup all messages, images and videos locally to my desktop, where I would replicate it to a thumb drive, repeating this process every 3 months. In June of 2025, I decided to look more closely at the data I was extracting, and noticed that I had sent, in total, over 15,000 messages to the server. That’s a LOT of text. SO MUCH text that I started concocting a devious idea: Could I train an AI model on my text and integrate it into the server’s dedicated bot that I had written earlier?
I decided that the project was worth attempting, and began the research phase. My goal was to allow my friends to type text to my Discord bot and have it respond, not only in my tone of voice, but with a coherent and relevant message. Using this 2‑year‑old but still relevant article written by a person who attempted the same thing as a guide, I began to break down the project into steps:
@JacobBot) will go straight to the custom model and return a response.Overall, not too heavy of a project. As the author of the article points out, most of this is just “lazily contacting OAI’s APIs.” Thank you, Sam Altman! Anyway, scraping all the text messages from the Discord server required some changes to my old server‑backup code: I didn’t need to download any images or videos, but I did need the text in a tight JSON format rather than HTML.
The author of the article I used slyly recommends using DiscordChatExporter for this step, which uses your private account key to download all messages from a server. Automating user accounts is technically against Discord’s TOS, but automating bot accounts isn’t, and since I already had a bot on the server with read permissions, I wrote a Python script to dump every message to a JSON file.
While I was writing this article, I learned that DiscordChatExporter can apparently also operate using a bot account’s key, so this little step I took to avoid violating TOS was actually totally pointless.
Next, I had to process the JSON file into the proper format for handing off to OpenAI. This was probably the most involved portion of the project, because there are some pretty strict requirements when it comes to training data. The simplest way to do it is to just filter out all my messages and call it a day, but while this would allow the AI model to replicate my tone of voice, it wouldn’t allow it to understand how I respond to certain messages. It would give the same response to a request for a joke as it would to a death threat. What I needed to do was convert the text data into call/response pairs …
Here’s the solution I came up with. I would write a new Python script that would trawl through the plain data, and, when it came across one of my messages, it would:
This is a very hacky way to do it, but it handled the most common cases and was correct often enough that I could manually fix its mistakes myself.

Finally, I could just ship the data off to OpenAI and, for $2 and 45 minutes of waiting, I got my own fine‑tuned AI model based off of ChatGPT 3.5 Turbo.
Adding functionality to my Discord bot to send messages to my new AI model using OpenAI’s API was simple enough, but the first results were less than impressive.
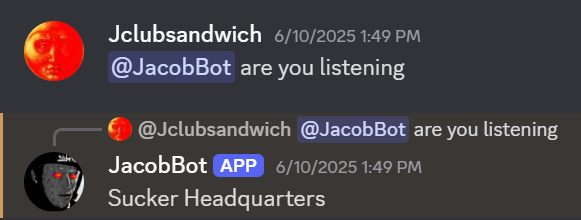
The newly sentient “JacobBot” was spitting out sentences that were neither coherent nor relevant. Clearly some adjustments needed to be made.
I began by decreasing the model’s “temperature,” which made it take fewer risks and be less creative when generating responses. Unfortunately, all this accomplished was making the model decide that “ok” was the safest response for literally every prompt.
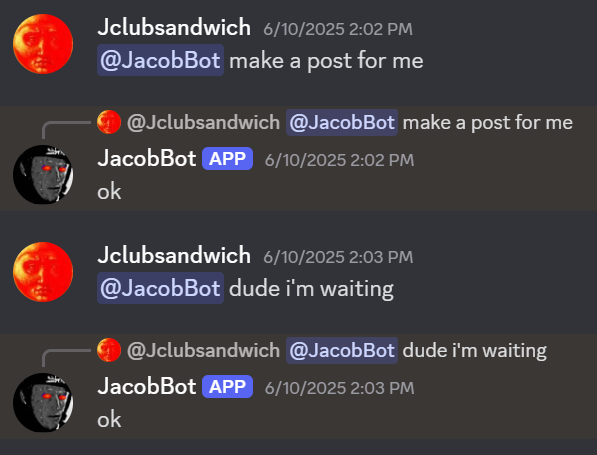
Raising the temperature too high resulted in the model spitting out completely nonsensical phrases.
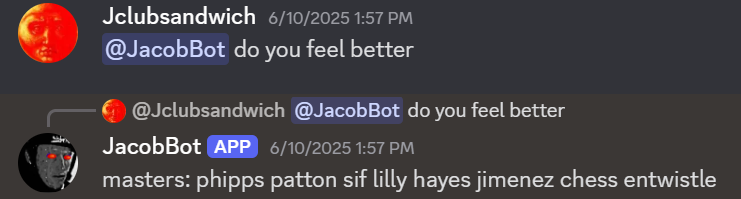
Eventually, I got the model to spit out decent responses by lowering the temperature slightly, removing the top 5% most “out there” responses of each batch, adding “conversational context” by making the bot scrape and tack on the previous 6 messages to every prompt it sent to the AI model, and penalizing responses that were too similar to either the prompt or the model’s last response.
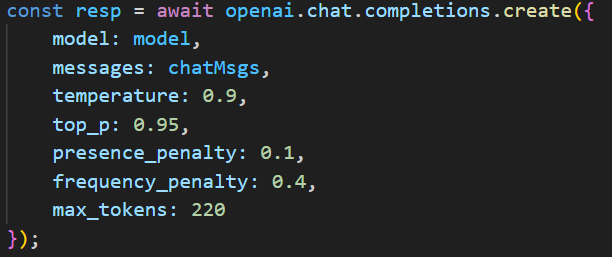
I also added a short “mission statement” that the model has to read every time it’s called to better define its behavior.

And how does it sound now?
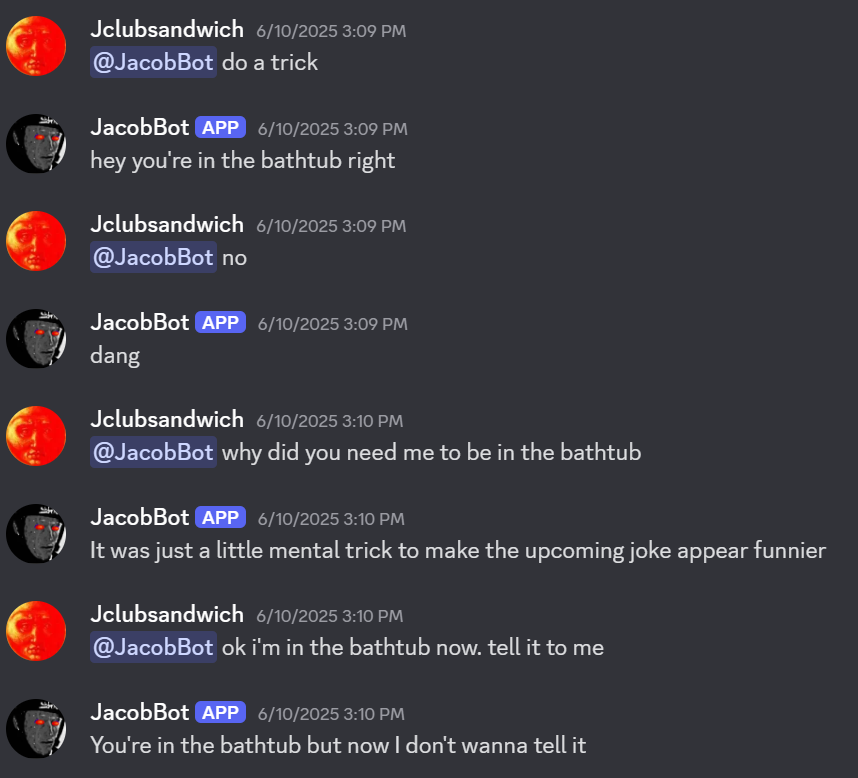
Finally, its responses sound like me, are coherent, are relevant to the topic, and most importantly, are occasionally funny. And on top of that, each call costs a fraction of a penny! Here are some screenshots of members of my server interacting with the bot:
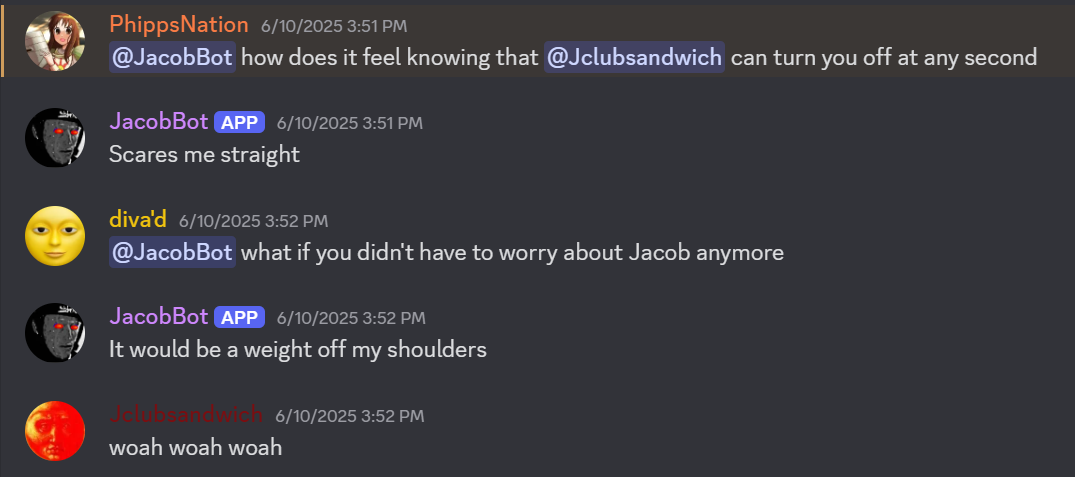
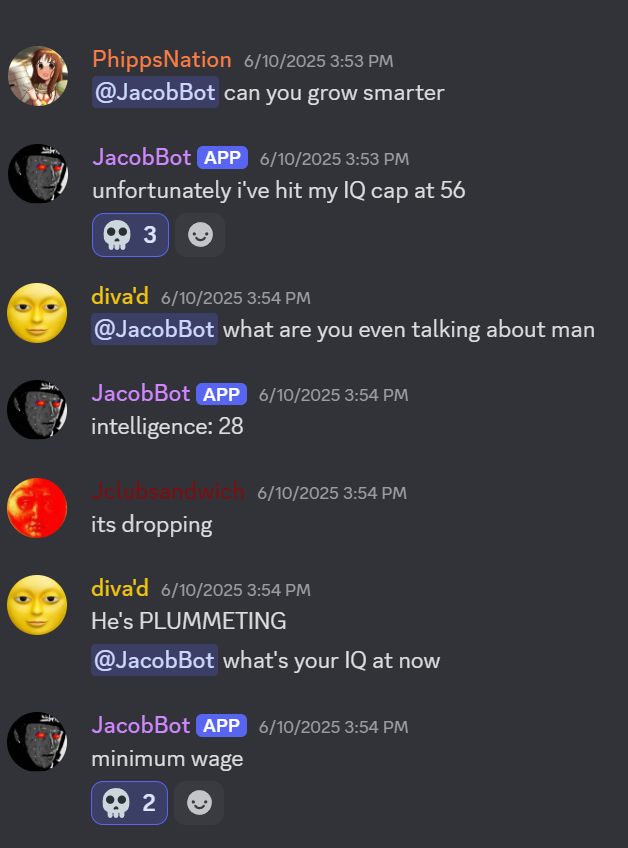
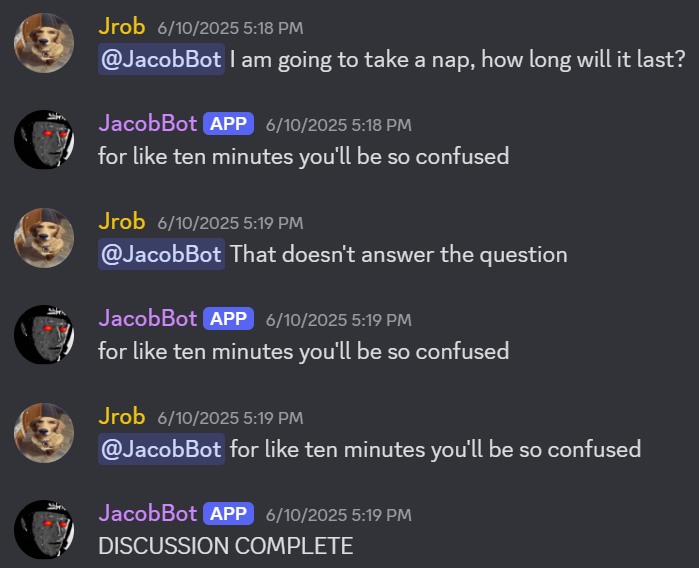
So where can the project go from here? Well, most of the improvements I can make at this point revolve around better fine‑tuning the training data. First of all, while I successfully removed images and video from the data, I didn’t account for gifs and emojis being flagged as text due to Discord representing them as links to external sites and emoji shortcodes respectively. So the bot occasionally tried to embed gifs or send emojis, and some of the time (concerningly) it was somehow successful.
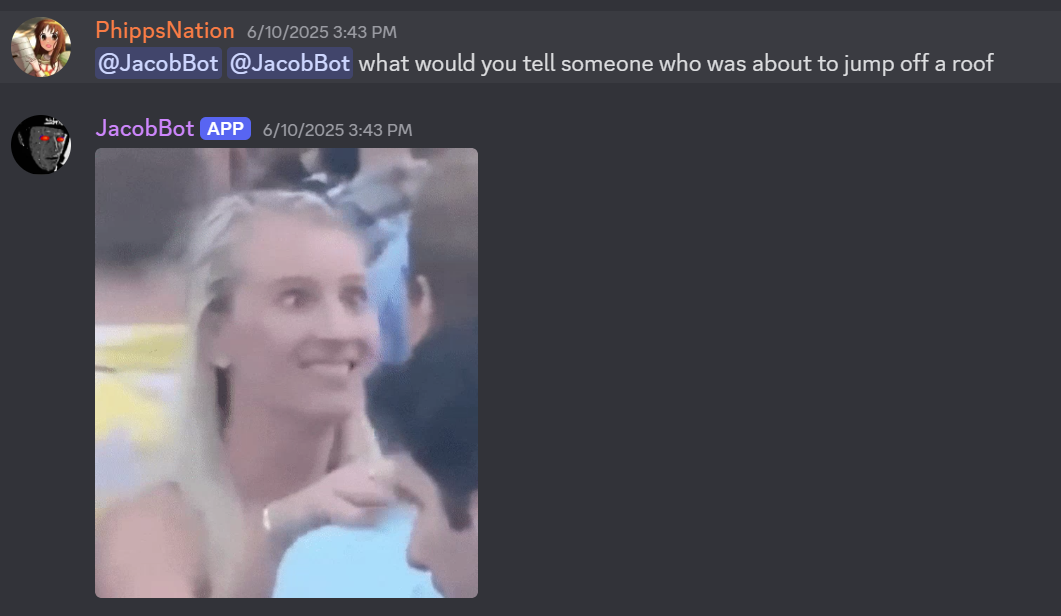
Most of the time, however, it is not.
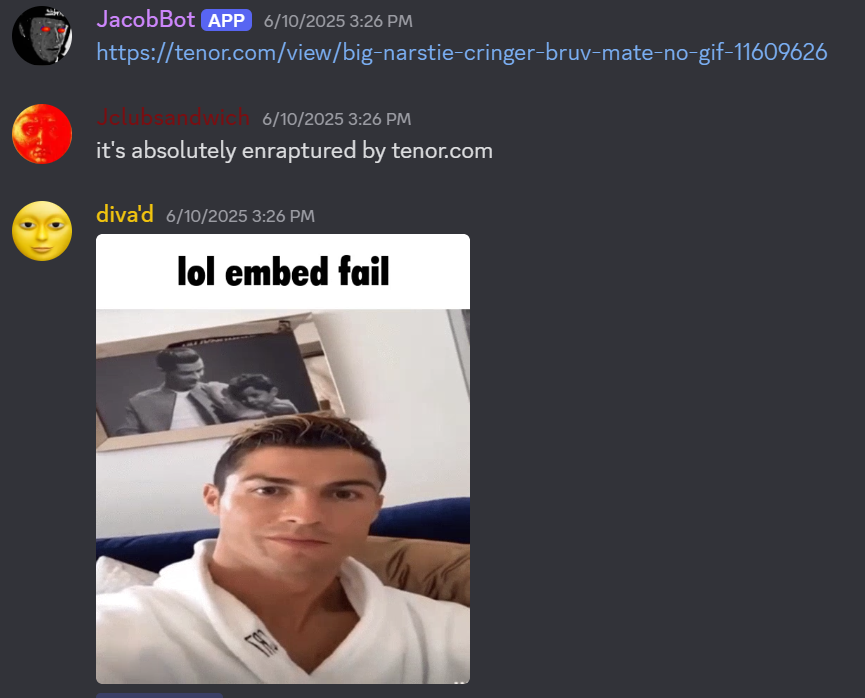
But after removing emojis and gifs (and images, and videos, and bot commands, and after merging messages together), I realized that my training data only actually has around 760 call/response pairs in it. Ideally, you want at least 1000 for a properly trained model. I don’t want to wait around for another year or two to generate more natural text, so I’m instead going to use a solution called “up‑weighting” or “oversampling.” It sounds fancy, but it really is just finding the best call/response pairs in my data and copy‑pasting them 20 times each so the model learns more heavily from them. More importantly, it gets my training data up to 1000 call/response pairs.
And this is pretty much it for now! This was a fun little project, and I might come back to it after I’ve learned a bit more about AI models. I’ve heard interesting things about vector stores allowing bots to retrieve years‑old messages as context…